最近公司有个项目,我需要写个小爬虫,将爬取到的数据进行统计分析。首先确定用 Python 写,其次不想用 Scrapy,因为要爬取的数据量和频率都不高,没必要上爬虫框架。于是,就自己搭了一个项目,通过不同的文件目录来组织代码。然而,这就绕不过模块和包,遇到了一些必踩的问题,一番研究之后,记录如下。
我的项目结构
首先,我并不是一个经验丰富的 Python 开发者,一般像我这样水平的,要么用框架,以其预置的代码结构来管理代码文件和逻辑;要么,就是调包侠,将代码写在同一个或多个 .py 文件中,不用文件目录组织,而是全部处于同一层级,这样方便各自互相调用。
对于有点追求的人来说,不用框架,自己搭建代码结构,当然希望代码之间有着合理的关系和逻辑,而不是一股脑的丢在一块儿,或更甚者,所有的业务逻辑全写在一个代码文件之中。
所以,我搭建了以下的代码结构:
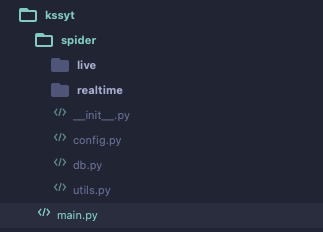
项目入口文件 main.py,负责所有爬虫的调度。爬虫的代码,全都放入 spider 目录,然后又分门别类的归入其各自类别的子目录:比如 live 目录存放跟直播相关的爬虫,realtime 目录存放与实时统计相关的爬虫。而 spider 目录其下,还存在一些在爬虫代码中需要调用的自定义工具模块文件:如 config.py 配置信息,db.py MySQL数据库操作快捷函数 和 utils.py 常用函数。
下面是完整的目录结构:
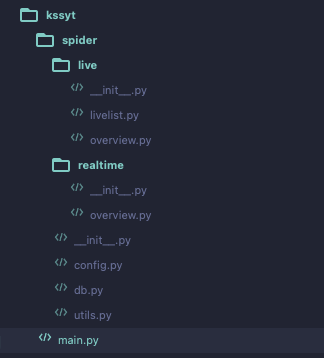
我希望我搭建的这个目录结构,能够按照预想的正常工作。然而,由于 Python 导包机制一套组合拳,让我一度陷入了迷茫。
我遇到的第一个问题
首先,来看一下我的 main.py 主程序:
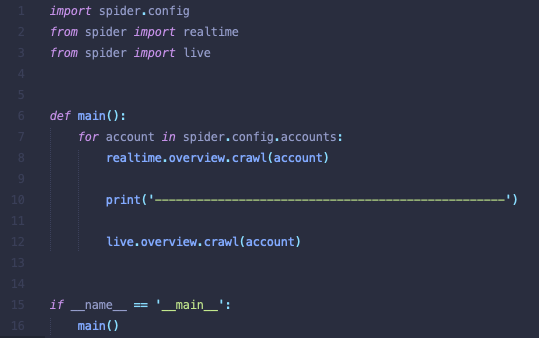
简单介绍一下业务逻辑,就是从多个直播账号中,去爬取数据,代码示例中的 realtime.overview.crawl(account) 和 live.overview.crawl(account) 就是分别从 实时统计 和 直播概览 两个不同页面接口去爬取数据。
请关注这里,realtime 和 live 两个目录,也就是 package 包,下面都含有 overview.py 模块文件,如果我在导入模块的时候,用下面这种方式,是会名称冲突的:
from spider.realtime import overview
from spider.live import overview
后导入的会覆盖前者。于是,就需要给它们各自加上别名:
from spider.realtime import overview as realtime_overview
from spider.live import overview as live_overview
好烦琐,那不导到 overview 模块这一级,而导到上一级各自的包,再用 包名.模块名 的方式调用,不香么。
在设计之初,我就考虑到了模块重名的问题,所以在 main.py 文件头部,我并没有 from 包 import 模块,而是 from 包 import 包,以避免模块命名冲突的问题。
想法是好的,但是很不幸,当我用 from spider import realtime 从 spider 包导入 realtime 包时,运行却报错了:AttributeError: module 'spider.realtime' has no attribute 'overview'。
基本概念
要解决上面的问题,需要先了解一些基本概念:什么是模块,什么是包,包里的 __init__.py 又是干什么的,以及 import 导包究竟做了什么事?
首先,模块的定义非常简单,一个 .py 文件其实就是一个 Python 模块,你可以将不同的业务逻辑代码,放在不同的模块文件中,最后通过相互之间的导入,来联合起来运行,形成一个整体的运行系统。
其次,虽然我们可以用模块来隔离不同的业务代码,但如果都一股脑儿的堆放在项目根目录下,项目的结构就过于扁平了,看起来是又臭又长。为了把业务的隔离,做的更立体化,使得功能相关性的模块聚在一起,就可以用文件夹,将模块分门别类的存放其中,这些文件夹,就是 package 包。包其实也是一种特殊的模块,你可以用 print(type(包名)) 打印出来看看,一定是 <class 'module'>。
在 Python 3.3 版本以前,文件夹下必须要包含一个 __init__.py 文件,此文件夹才会被视为包,而 Python 3.3 版本之后,文件夹直接被视为包,无须显式的包含 __init__.py 文件。
然而为了兼容性,和很多时候确实需要 __init__.py 文件,所以建议将此文件,始终新建放入要作为包的目录中,这也是用 PyCharm 创建包的默认操作。
那么 __init__.py 初始化文件,到底是干什么的。顾名思义,就是做初始化用的。你可以在此文件中,导入其他模块,定义 变量、函数、类 等,进行一些预定义的工作,然后在用 import 导入包或包里的模块时,被导入的包下的初始化文件会被自动调用执行。
最后,import 导入究竟做了什么事。从本质上来讲,import 会把要导入的模块或包,执行一遍,然后将里面导入的其他模块,和定义的 变量、函数、类 等都保存在此模块独立的名称空间中,并且被导入的模块自身的名称符号,也会加入引用者自己的名称空间,这样在导入后只需用 模块名.符号名 的方式,来引用其中的变量、类或调用其中定义的函数,而不必担心命名冲突的问题。
那如果,导入的不是模块,而是一个包,比如 from spider import realtime,spider 和 realtime 都是文件夹,也就是包,那会执行什么代码呢?其实执行的是包里的 __init__.py 初始化代码,而且这两个包的初始化文件代码,都会依次执行。
不论导入的是模块,还是包,模块代码和包的初始化代码,只会执行一次,后续无论再用 import 导入相同的模块或包多少次,其初始化代码均不会重复执行。
最后的最后,我知道可能有些人已经不耐烦了,原理性的东西,是有些烦琐,马上就完,暂且忍耐一下下。我们想看当前通过 import 已经导进来了哪些变量、函数、类、模块或包,我们可以用 dir() 函数,来查看当前作用域内有哪些名称符号。比如,修改上面报错的代码如下:
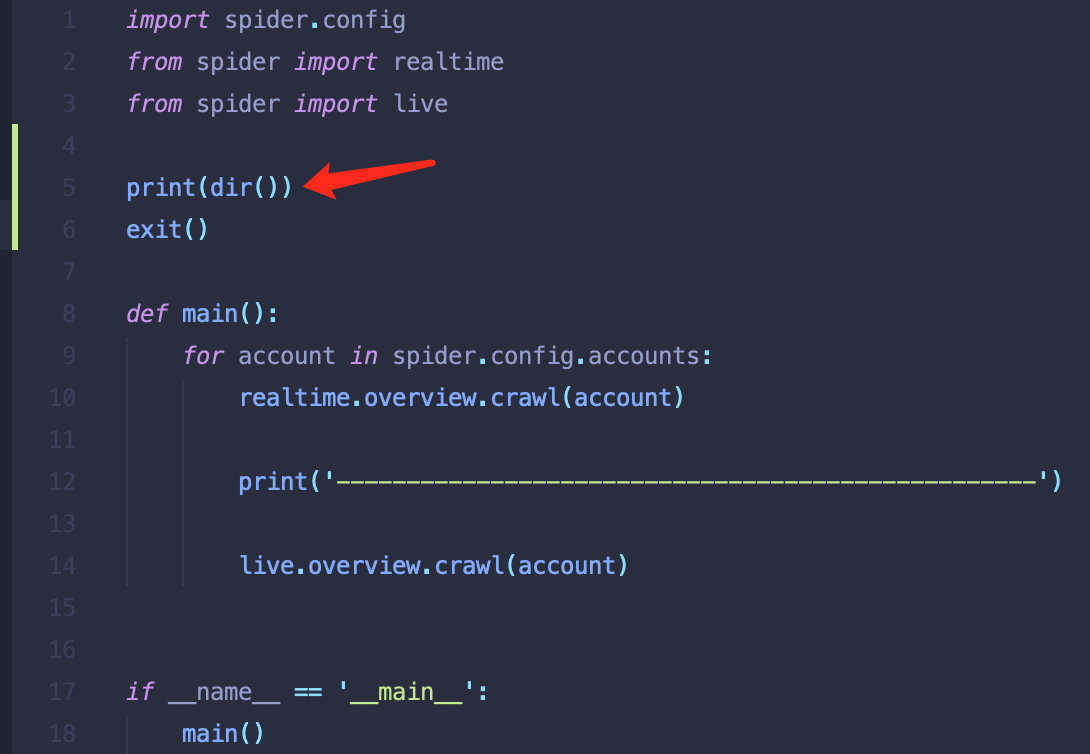 看下执行结果:
看下执行结果:
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'live', 'realtime', 'spider']
前面一堆,是 Python 内置名称符号,拉到最后,可以看到我的程序自己的名称符号:live、realtime 和 spider,它们是通过 import 导进来的。
dir() 函数还可以传入参数,来看传入的对象的名称符号。上面报错信息说,我的 realtime 下没有 overview 属性,那我们就把 realtime 传入 dir() 函数:dir(realtime),来看看其中有什么:
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__']
一堆内置符号,果然没有 overview。至此了然,上面的报错:spider.realtime 下没有 overview,也就不足为奇了,可怎么解决?
解决第一个问题
既然 from spider import realtime 是从 spider 包导入 realtime 包,期间会依次执行各自的 __init__.py,我们只需在 realtime 包下的 __init__.py 文件中,导入需要的 overview 模块,这样 realtime 私有名称空间中就有了 overview 名称符号,我们就可以用 realtime.overview 来调用此模块下面的函数了。
Let's do it.
首先,在 realtime 目录下的 __init__.py 文件加入代码:from . import overview。这里牵扯相对导入,后文再说。
然后,重新运行带有 dir(realtime) 代码的主程序,来看看名称符号的输出:
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'overview']
与预期一致,多了 overview,最后,删除测试代码,重新运行主程序,不再报错,正常运行了。
后面如法炮制,live 目录下,也有两个模块文件:livelist.py 和 overview.py,同样需要在 __init__.py 文件中加入导入模块的代码:
from . import livelist
from . import overview
如此,我们便可以通过 包名.模块名 的方式,来访问其中的模块了。
绝对导入与相对导入
我之前所用的 import 导入方式,除了在 __init__.py 中的是相对导入以外,其余均是绝对导入。
当我在 spider/realtime/overview.py 文件中,写爬虫的实际业务逻辑代码时,我又遇到了相对导入和绝对导入的问题。
先看一下爬虫代码:
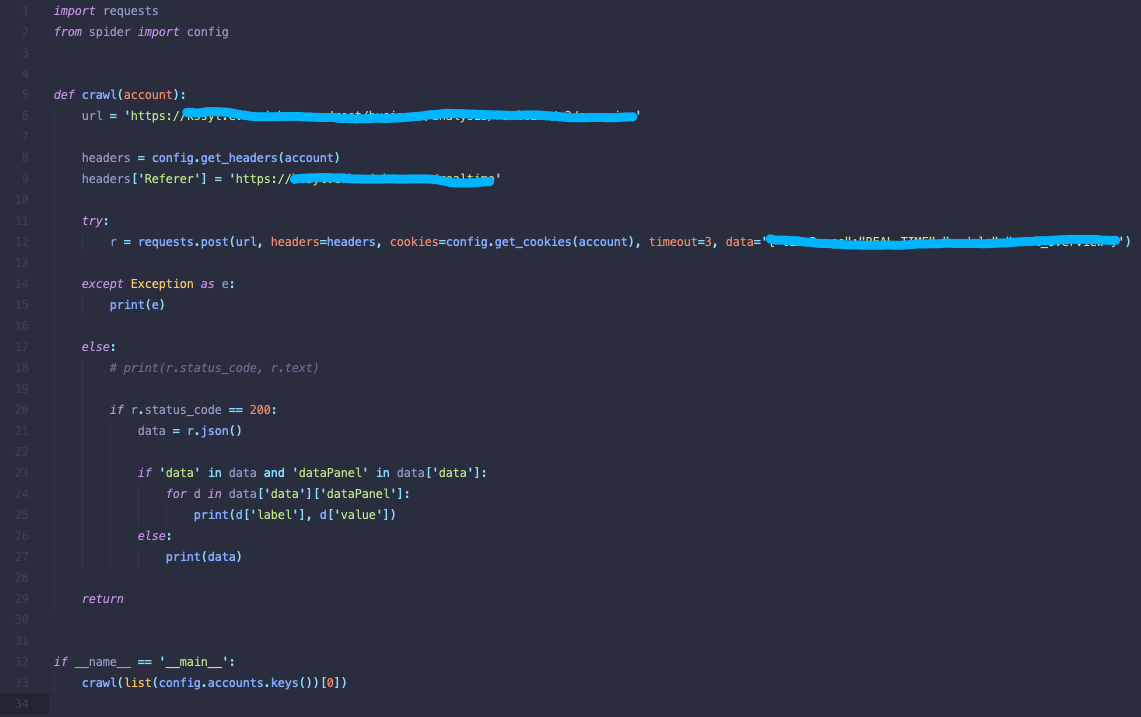
最上方的 from spider import config 是从 spider 包导入 config 模块,里面存放了爬虫爬取信息需要的登录账号和 HTTP HEADER 相关配置信息。此处用的是绝对导入。
当我从项目根目录的 main.py 主程序运行时,一切正常。可是,通常情况下,对于每个自己写的模块,我们都希望能够单独运行它,进行局部的模块测试,而无须依赖主程序。所以,在此模块代码的最下方,我写了如下代码:
if __name__ == '__main__':
crawl(list(config.accounts.keys())[0])
稍微有点经验的 Python 开发者,都知道这是干什么的。当某个模块,以 script 脚本的方式运行时,其 __name__ 的值一定是 __main__ 字符串,所以可以用这个技巧,用来在此判断分支中,写模块测试代码,而不用担心此模块被 import 导入时,最下方的测试代码也会被执行。
然而,当我想以脚本的形式,运行此模块,进行测试的时候,却又报错了:ModuleNotFoundError: No module named 'spider'。
这是因为 Python 脚本在运行时,会默认将脚本所在的当前目录加入 sys.path 中,以便于在其中查找你要导入的模块,而当我用 python spider/realtime/overview.py 以脚本的方式运行模块时,此时 overview.py 所在的当前目录为 xxx/spider/realtime,于是 Python 解释器就会在 realtime 目录及其子目录下,去查找要导入的模块。而 from spider import config 中的 config 模块,很明显位于 realtime 当前目录的上一层 spider 中,而它却不在 sys.path 的查找范围中,所以自然报错说:找不到 spider 模块。
既然执行模块脚本时,脚本程序无法以绝对导入的方式,引用父级目录中的模块,那么我用相对导入的方式,是否可以解决?
于是,我将代码调整为相对导入:from .. import config。
--spider
--|--config.py
--|--realtime
----|--overview.py
以当前模块所在的包 realtime 为基准,从 .. 上级目录 导入 config 模块。看起来合情合理,运行一下看看。
首先,运行主程序 python main.py,一切正常。再以脚本的形式运行模块 python spider/realtime/overview.py,报错:ImportError: attempted relative import with no known parent package。
经过一番搜索,查阅了一些文章,终于搞明白,原来在 Python 中,相对导入的实现,是极度依赖 __name__ 内置变量的。当模块以 import 导入的方式加载调用时,其模块的 __name__ 变量会含有包名和模块名这些重要信息,以用于相对导入;而当模块以脚本的方式直接运行时,其 __name__ 的值始终为 __main__ 字符串,则相对导入无法从中分析出父级包的信息,自然会报上面的错误:“尝试从未知的父包中进行相对导入”,了然。
二者选其一,如何抉择
绝对导入和相对导入都不能满足我想要的效果:既支持从主程序执行,也支持单独测试某个模块。而现在,二者在不做任何特殊处理的情况下,均不支持单独以脚本直接执行的方式,测试某个模块。要如何解决?
解决方案有3种,前两种针对绝对导入,最后一种针对相对导入。
- 使用 sys.path.append() 追加类库搜索目录【极不推荐】
既然
sys.path中不包含我们期望的路径,那么我们可以通过sys.path.append(xxx)手动的将要包含的路径追加进去。比如:import sys sys.path.append('..') # 这里可用相对路径,也可用绝对路径 from spider import config此方案不再赘述,因为代码丑陋,耦合过紧,兼容性和可移植性差,极不推荐。
- 设置 PYTHONPATH 环境变量 【推荐】
在 Python 中,其实我们还可以通过设置
PYTHONPATH环境变量的方式,来指定追加的类库搜索目录,底层原理等同于使用sys.path.append(),但此方案非常简洁,且PyCharm就是用这种方式,支持模块直接以脚本方式运行,而又能使用绝对导入的。在 Windows 中,可以在命令行中使用
set PYTHONPATH=项目绝对路径命令,设置此环境变量。在 Linux 或 Mac 上,通过
export PYTHONPATH=项目绝对路径设置此环境变量。为了更省事,我在 virtualenv 的 bin 目录的 activate 激活虚拟环境的 shell 脚本中,加入了
PYTHONPATH环境变量设置的代码,这样,在用source venv/bin/activate激活虚拟环境后,PYTHONPATH环境变量也就自动设置好了。Windows 下的同理。 - 使用 python -m xxx.xxx.模块名 的运行方式,测试模块【不推荐】
在包中的模块代码,使用相对导入的方式,运行时不要采取
python xxx/xxx/xxx.py脚本运行的方式,而是采取模块运行的方式:python -m xxx.xxx.模块名,前面的 xxx 是包名,这样,模块的__name__值就会包含实际的包名和模块名,可以让相对导入正常工作。但是,此方案一是有违正常 Python 程序运行的习俗,二是在
PyCharm中的某个模块文件,直接右键运行时,是默认采取python xxx/xxx/xxx.py的方式执行的,所以此方案不推荐。
由此看来,我推荐的方式是,大多数情况下,总是以绝对导入的形式,来引用你项目的包和模块。那相对导入就无用武之地了吗?还记得上面的 __init__.py 么,那里头用的就是相对导入,因为我们永远不会以脚本的方式直接运行 python xxx/__init__.py,所以,这里头的相对导入,永远都是安全的。
并且,如果你正在写一个类库,写完之后要发布出去,分发给全世界的人去用,那么你写的这个工具包里头的代码,都要使用相对导入来引用本地的包和模块。
而通常情况下,我们自己写的包和模块,仅仅在本项目内使用,完全可以借助于 PYTHONPATH 环境变量,使用绝对导入来引用本地任意模块,使用相对导入在 __init__.py 中引用包中的模块。
小彩蛋
上文提到,import 的过程,实际上就是把要导入的包和模块的名称,加入 Python 的符号表中,也就是官方文档上说的 namespace【名称空间】,并且用 Python 内置的 dir() 函数,可以打印当前的作用域中,加载了哪些名称符号。
而我在使用 pymsql 第三方包时,看到其官方文档上的示例代码,感到有些迷惑:

我原先的错误认知是,import pymysql.cursors ,我就只能引用 pymysql.cursors,而如果想再引用上一级 pymysql,则需像下面这样:
import pymysql
import pymysql.cursors
但看了 pymsql 的示例代码后,我经过了一番认真的思索和测试,领悟到,原来 import pymysql.cursors 仅仅是先将 pymysql 这个名称符号,加入到当前正在运行的模块的名称空间内,再将 cursors 加入 pymysql 的私有名称空间内,用 dir() 和 dir(pymysql) 分别打印当前运行的模块和 pymysql 包的名称符号列表后,可以看的很清楚,而有了 pymysql 的名称符号,自然可以在其私有的名称空间下,继续引用 pymysql.cursors,继而在 pymysql.cursors 模块下,再继续引用 pymysql.cursors.DictCursor。
但当你换了一种导入方式后,则完全不同了:from pymsql import cursors,这只会将 cursors 加入当前符号表,只能引用 cursors,而 pymysql 不在当前模块的名称空间内,所以无法直接引用,比如:pymysql.connect(...) 的调用,就会报错:NameError: name 'pymysql' is not defined。
总结
最后吐槽一下,Python 的模块和包的导入机制,确实让人迷惑,这在我查阅资料的时候,看到好多国外开发者都吐槽过。并且它支持导入包、模块、变量、函数、类等,在使用一些第三方类库的包和模块时,参考它们的官方文档写代码,你压根就不知道,你导进来的到底是个什么东西,让人心里很没底。在这一点上,Java 就很清晰,它导进来的,一定是类。
本文以我正在实际开发的一个小爬虫项目为背景,讲述了项目搭建从鸿蒙初开到迷雾散尽的整个心路历程,期间由于自己在 Python 上的储备不够,又翻阅了大量的网上资料,潜心研究、领悟,最后融会贯通,写就此文。
此项目看似麻雀虽小,但五脏俱全,在模块和包的整体工作机制上,各个原理、特性和缺陷均有体现,是 Python 开发者绕不过去的一道坎。
希望此文做到了深入浅出,不同层次的 Python 开发者都可以从中有所收获,如果这篇文章对你有帮助,请不吝给作者点个推荐,也不枉我呕心沥血成此长文。